Research
Multi–agent reinforcement learning (MARL) has been an active field of research for over a decade. However, research pushing the field toward real-world use cases is less common.
Our research provides a first look at the potential of MARL in an agricultural setting. We focus on the use case of harvesting windfall apples and expect this technology to be easily transferable to other crops like oranges or walnuts.
Research in this field has largely been conducted in simple, 2D environments that minimally represent real-world circumstances. InstaDeep’s Jumanji research library, for example, offers 22 such environments. We provide a novel environment developed based on field measurements of real apple orchards. This environment randomly generates an orchard with real-world dimensions where agents are trained to carry out the task of collecting windfall apples. In conducting this research, we achieve the first step toward deploying a robotic fleet to collect windfall fruit and contribute valuable insight for the research community on the viability of MARL in real world settings.
Our new environment and MARL implementation are fondly referred to as Applesauce. Check it out on Github.

Approach
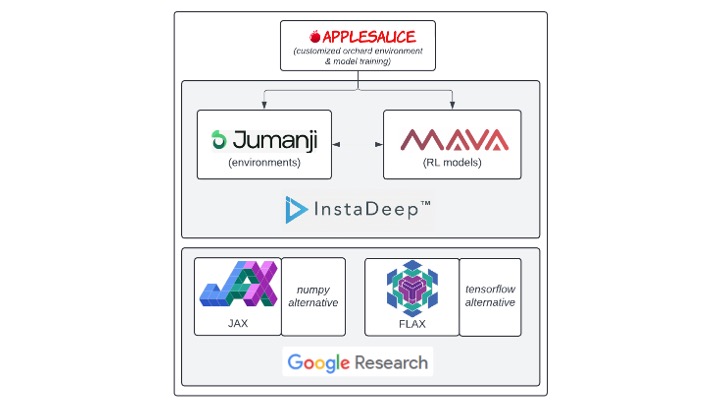
A MARL implementation of this use case, fondly referred to as “Applesauce”, was adapted from the Jumanji and Mava research libraries. Both libraries are research tools developed by InstaDeep to speed the rate of MARL research. Because training MARL algorithms requires billions of training steps, parallelization is key to efficient research and development. Mava, Jumanji, and our Applesauce implementation are all built using Google’s Jax and Flax python libraries, which enable parallel computation with minimal code changes.
Environment
At the core of our research is a novel environment for testing assumptions for the robotic harvesting use case. To this end, our team leveraged field measurements across ten apple orchards near Watsonville, CA to inform realistic dimensions of orchards as well as their tree density. Applesauce’s infrastructure randomly generates orchards with different dimensions so that a variety of orchard environments are included in the training and evaluation processes.
What apple orchards actually look like:

A sample of the AppleSauce environment:
In addition to a more realistic layout, we improve upon currently available environments by:
-
Establishing agents with a much larger action space: Agents can rotate to almost any angle, enabling more targeted movements across the orchard. This is a step beyond Jumanji’s Level-Based Foraging environment, which limits agents’ range of motion to forward, backward, left or right.
-
Implementing a continuous environment space: Whereas other research environments use a discrete environment space (sometimes referred to as a grid world), the Applesauce environment allows agents to navigate to any point in continuous 2D space. This results in a larger set of possible environment states and more sparse positive rewards, making this a much larger and more challenging training task.
-
Adding multiple agents with purpose-built roles: Our research will incorporate two types of moving agents: (1) picker bots that move around the orchards to pick up apples and deposit them in bins and (2) moveable bins that auto-locate to reduce the distance traveled for picker bots. The design of agent roles was intentionally chosen for mininally-disruptive deployment of this technology in the field.
Model Training
At a high level, reinforcement learning trains a model to interface with an environment. At each time step, the model receives information on the state (or observation) of the environment as well as its reward based on previous actions, and outputs a next action to take with the goal of maximizing its rewards. The Applesauce infrastructure follows this concept, using multi-agent proximal policy optimization (MAPPO) for training.
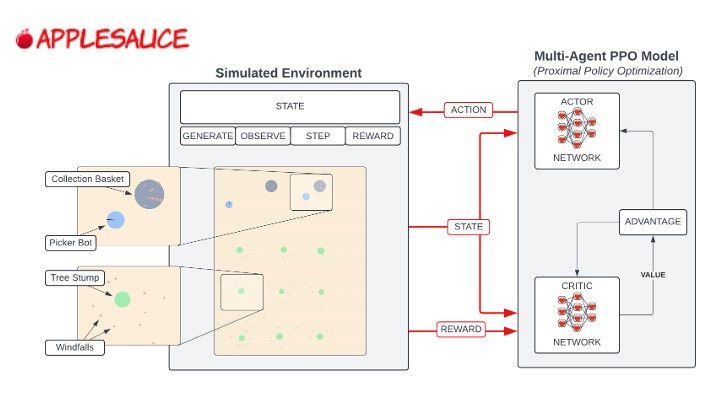
Training Architecture: The Multi-Agent Proximal Policy Optimization (MAPPO) training architecture is well suited for cooperative tasks such as ours. Proximal policy optimization controls the size of policy updates, increasing the likelihood that the model converges which is not always the case for MARL. MAPPO further incorporates a centralized value function for calculating the Generalized Advantage Estimation (GAE) of all agents’ actions, resulting in more collaborative behavior overall. Further information on MAPPO and other forms of proximal policy optimization can be found at MarlLib or HuggingFace.
Reward Function: Critical to any reinforcement learning model is a well-thought out reward function, lest your agents fool you by finding a loophole! Through qualitative observation and fine tuning, we developed a complex set of positive and negative rewards:
- Positive rewards for:
- picking up an apple
- dropping an apple in the bin
- Negative rewards for:
- out of bounds
- taking a step
- improper attempt to pick up
- improper attempt to drop
- dropping an apple not in bin
- no action (noop)
- colliding
- hoarding
Evaluation
We measure the performance of MARL against two different baselines. The first is an algorithmic A* baseline which directs agents to the nearest apple from the agent. The second, more interesting, is the human baseline. Would it be possible for these agents (or robots in the physical world) to outperform humans?
Our primary evaluation metric is the amount of apples collected per hour. We use best practices for statistically significant evaluation based on the principles documented by Gorsane, et al.
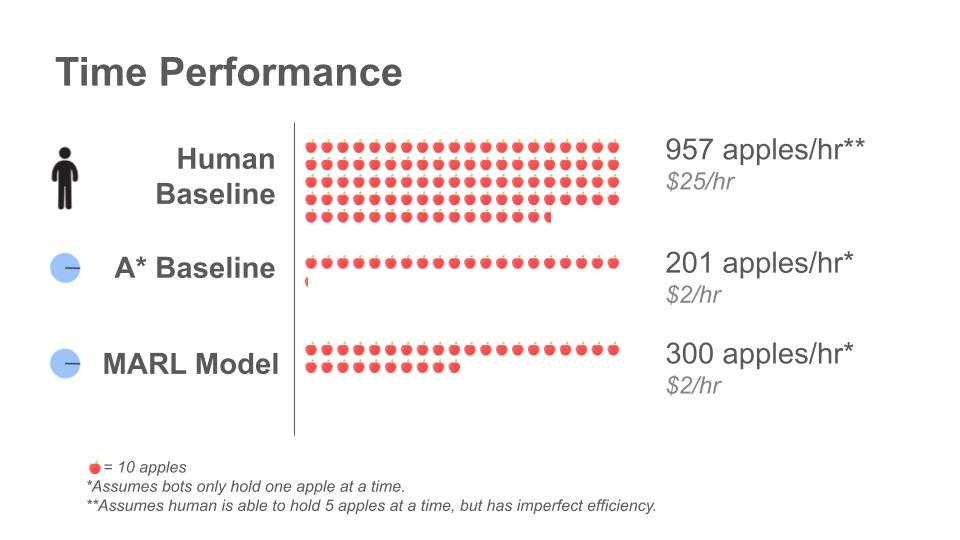
The MARL algorithm beat out the algorithmic (A*) baseline, but humans are still expected to be faster at this early stage. Despite a human’s time efficient performance, certain benefits of robotic deployment mean this result is still promising. A robot is ‘always on’ and can pick windfallen apples as soon as they fall, increasing farmers’ yield of usable windfall apples. When considering the estimated cost per hour of these 24/7 workers, the humble robots become much more attractive.
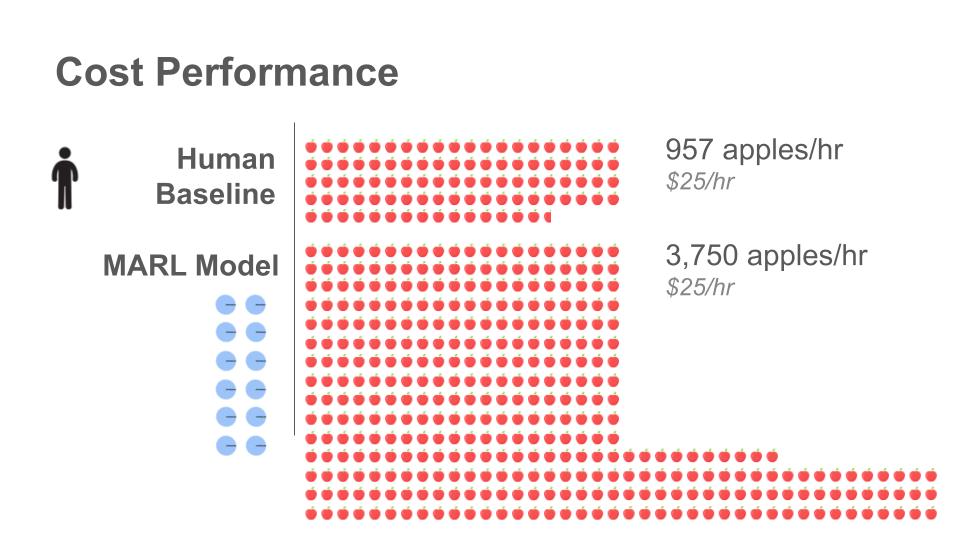
We expect this increase in produce yield, coupled with the increasing affordability of robotic deployment, mean a strong upside for farmers to deploy robotic fleets. Further, it is possible to deploy robots that can carry more than one apple at once, a feature which would close the gap between human and robotic time-performance.
Key Learnings & Impact
This project provided an excellent opportunity to connect experts in the field of agriculture with those in MARL research. Our guiding light has been to improve our agricultural systems and reduce food waste through robotic deployment, and we were excited to learn how open the agricultural community is to adopting new technologies! Our initial research validated our hypothesis that MARL provides a more performant system than A* for simulated robotic harvesting of windfall apples.
The new Applesause environment and supplemental MARL infrastructure is available for other researchers in the field to work with and build on. We hope our research will inspire future work and serve as a benchmark for more agriculture-focused use cases within the MARL research community.
Future Work
The Windfallen team intends to publish research in 2025 after adding a few additional components to our system. Namely, we will incorporate moveable bins to reduce the travel time for picker agents and incorporate fog of war to simulate agents being dropped in a new, unmapped space. Beyond these features, future work could move toward adding a time-series component for short term memory, advancing to a 3D environment, and tuning communication methods between agents.